Chapitre 26 Bases sur les réseaux
Internet, ce n’est pas un espace virtuel, un nuage d’information abstrait où l’on trouve tout et n’importe quoi. En tout cas ce n’est pas seulement cela.
Ce qu’on appelle Internet est avant tout un ensemble de réseaux195. Des millions de réseaux, agrégés sur plusieurs décennies et, de façon plus ou moins chaotique, gérés aussi bien par des entreprises, des universités, des gouvernements, des associations que des particuliers ; des millions d’ordinateurs et de matériaux de tous types, reliés entre eux par des technologies très diverses, allant du câble de cuivre à la fibre optique en passant par le sans-fil.
Mais pour nous, derrière notre petit écran, Internet c’est avant tout ce qu’il nous permet de faire : visiter des sites web, envoyer des emails, tchatter avec des gens ou télécharger des fichiers. De nouvelles applications apparaissent en permanence et seule l’imagination humaine semble en limiter les possibilités.
Comprendre comment fonctionne Internet et comment se protéger, c’est décortiquer cette complexité afin de comprendre comment ces ordinateurs communiquent entre eux ; mais aussi comment fonctionnent les diverses applications que l’on utilise.
26.1 Des ordinateurs branchés entre eux
Assez tôt dans l’histoire de l’informatique, il est apparu nécessaire, notamment dans le travail universitaire et dans le domaine militaire, de faire en sorte que des ordinateurs puissent partager des ressources ou des informations — et ce, à des distances de plus en plus grandes. Ainsi sont nés les réseaux informatiques. On a d’abord relié des ordinateurs les uns aux autres dans un lieu restreint — généralement une université, une entreprise ou un site militaire —, puis on a relié ces lieux entre eux. Aux États-Unis, à la fin des années 1960, est créé ARPANET (Advanced Research Projects Agency Network), un réseau qui reliait les universités dans tout le pays. Pour sa mise en place et son amélioration ont été inventées une bonne partie des techniques utilisées aujourd’hui avec Internet. La naissance d’Internet est liée à celle des logiciels libres, et il fonctionne selon des principes similaires d’ouverture et de transparence196, ce qui n’empêche pas qu’au départ il a été développé pour répondre à des besoins militaires.
Les différents réseaux informatiques ont été interconnectés, constituant ainsi Internet, qui se développe de façon importante depuis les années 1990.
De plus en plus d’objets — dont la fonction première n’est pas d’être un ordinateur — sont connectés à Internet : des caméras de surveillance197, des radars routiers198, des bornes PMU199, des télés200, des frigos201, des équipements médicaux202, des jouets pour enfants203, des voitures204, etc. Certaines personnes parlent même d’Internet of Shit205 (« l’Internet des objets de merde ») afin de montrer l’absurdité de nombre d’objets qui font leur entrée sur Internet.
26.1.1 Un réseau d’ordinateurs
« Un réseau est un ensemble de nœuds […] reliés entre eux par des liens »206. Dans un réseau informatique, les nœuds sont des ordinateurs. C’est donc un ensemble d’ordinateurs reliés entre eux par des câbles, des ondes, etc.
Les ordinateurs qui font partie des réseaux ne ressemblent pas tous aux ordinateurs personnels, fixes ou portables, que l’on utilise en général. Certains sont en effet spécialisés pour assurer des fonctions particulières au sein du réseau. Ainsi, la « box » qui permet à la plupart d’entre nous d’accéder à Internet est un petit ordinateur ; de même, les serveurs sur lesquels sont enregistrés les sites web sont aussi des ordinateurs. D’autres types d’ordinateurs spécialisés pourraient encore être ajoutés à cette liste : on en découvrira certains dans les pages qui viennent.
26.1.2 Carte réseau
Malgré leurs différences, tous les ordinateurs connectés à un réseau ont nécessairement un point commun : en plus du matériel minimum qui compose un ordinateur, ils doivent disposer d’au moins un périphérique qui sert à se connecter au réseau. On l’appelle carte réseau. Elle permet d’établir le lien avec d’autres ordinateurs. De nos jours, plusieurs cartes réseau sont souvent intégrées dans tout ordinateur personnel (une carte réseau filaire et une carte Wi-Fi par exemple).
Chaque carte réseau possède une adresse matérielle, qui l’identifie de façon plus ou moins unique. Dans la technologie filaire domestique, appelée Ethernet, comme dans la technologie sans-fil Wi-Fi, cette adresse matérielle est appelée adresse MAC. L’adresse MAC livrée avec la carte est conçue pour que la probabilité que deux cartes réseau possèdent la même adresse matérielle soit très faible207, ce qui n’est pas sans poser problème en matière d’anonymat, comme nous le verrons plus loin.
26.1.3 Différents types de liens
Les façons les plus courantes de connecter des ordinateurs personnels en réseau sont soit d’y brancher un câble, que l’on appelle câble Ethernet, soit d’utiliser des ondes radio, avec le Wi-Fi.
)")
Un connecteur Ethernet standard RJ-45
Mais au-delà de notre prise téléphonique, nos communications sur Internet sont transportées par bien d’autres moyens. Il existe de nombreux supports pour transmettre l’information : câble de cuivre, fibre optique, ondes radio, etc. De la transmission par modem208 des années 1990 à la fibre optique209 utilisée pour les connexions intercontinentales, en passant par l’ADSL210 des années 2000, chacun d’eux a des caractéristiques différentes, notamment en termes de débit d’information (également appelé bande passante) et de coût d’installation et d’entretien.
Ces différentes technologies n’ont pas les mêmes faiblesses vis-à-vis de la confidentialité des communications qu’on leur confie ou des traces qu’elles laissent : il sera ainsi plus facile d’intercepter à distance un signal radio diffusé à la ronde que de la lumière qui passe à l’intérieur d’une fibre optique.
26.2 Protocoles de communication
Pour que des machines puissent se parler, il ne suffit pas qu’elles soient reliées entre elles, il faut aussi qu’elles parlent une langue commune. On appelle cette langue un protocole de communication. La plupart des « langues » utilisées par les machines sur Internet sont définies de façon précise dans des documents publics211 : c’est ce qui permet à des réseaux, à des ordinateurs et à des logiciels variés de fonctionner ensemble, pour peu qu’ils respectent ces standards. C’est ce que recouvre la notion d’interopérabilité.
Différents protocoles répondent à différents besoins : le téléchargement d’un fichier, l’envoi d’un email, la consultation d’un site web, etc.
Pour simplifier, nous détaillerons ci-dessous ces différents protocoles en les classant en trois catégories : protocoles physiques, réseau, puis applicatifs212.
Et afin de bien comprendre, quoi de mieux qu’une analogie ?
Comparons donc le voyage de nos informations à travers Internet à l’acheminement d’une carte postale, dont les étapes, du centre de tri postal à la boîte aux lettres, correspondraient aux différents ordinateurs traversés.
26.2.1 Les protocoles physiques
Afin de livrer notre courrier à bon port, plusieurs moyens de transport peuvent être utilisés successivement : avion, bateau, camion, ou encore bicyclette.
Chacun de ces moyens obéit à un certain nombre de règlements : code de la route, aiguillage aérien, droit maritime, etc.
De même, sur Internet, les diverses technologies matérielles présentées précédemment impliquent l’usage de différentes conventions. On parle dans ce cas de protocoles physiques.
26.2.2 Les protocoles réseau
Savoir naviguer n’est pas suffisant pour acheminer notre carte postale. Il faut également savoir lire un code postal et posséder quelques notions de géographie pour atteindre la destinataire, ou du moins le centre de tri le plus proche.
C’est là qu’interviennent les protocoles réseau : leur but est de permettre l’acheminement d’informations d’une machine à une autre, parfois très éloignées, indépendamment des connexions physiques entre ces machines.
Le protocole réseau le plus connu est le protocole IP.
26.2.3 Les protocoles applicatifs
On se sert souvent d’Internet pour accéder au web, c’est-à-dire un ensemble de pages accessibles sur des serveurs, que l’on consulte à partir d’un navigateur web : https://guide.boum.org est un exemple de site web. Les applications web utilisent un protocole nommé HTTP, dont la version chiffrée et authentifiée est HTTPS. Le langage courant confond fréquemment le web avec Internet, avec des expressions comme « aller sur Internet » par exemple. Or, le web n’est qu’un des nombreux usages d’Internet.
Il existe en fait de très nombreuses applications qui utilisent Internet, que la plupart des internautes n’ont pas conscience d’utiliser. Outre le web, on peut ainsi citer le courrier électronique, la messagerie instantanée, le transfert de fichiers, les cryptomonnaies, etc.
Ainsi, vous pourrez rencontrer ces différents protocoles qui, s’ils utilisent Internet, ne sont pas du web :
- SMTP, POP, IMAP sont des protocoles utilisés dans la messagerie électronique213, dont il existe également des versions chiffrées et authentifiées (SMTPS, POPS, IMAPS) ;
- Skype, Signal, IRC et XMPP sont des protocoles utilisés dans la messagerie instantanée ;
- BitTorrent est un protocole de partage de fichiers en pair à pair.
En fait, une personne qui a des connaissances suffisantes en programmation peut créer elle-même un nouveau protocole et donc une nouvelle application d’Internet.
Chaque application d’Internet utilise ainsi un langage particulier, appelé protocole applicatif, et met ensuite le résultat dans des « paquets » qui sont transmis par les protocoles réseau d’Internet. On peut comparer le protocole applicatif à la langue dans laquelle on écrit le texte d’une carte postale : il faut que l’expéditrice et la destinataire comprennent cette langue. Cependant, la Poste n’a pas besoin d’y comprendre quoi que ce soit, tant que la lettre contient une adresse valide.
En général, les cartes postales ne sont pas mises dans des enveloppes : n’importe qui sur la route peut les lire. De même, la source et la destination écrites dans l’en-tête des paquets sont lisibles par quiconque. Il y a aussi beaucoup de protocoles applicatifs qui ne sont pas chiffrés : le contenu des paquets est dans ce cas lui aussi lisible par quiconque.
Les protocoles applicatifs ne sont pas tous transparents. Si beaucoup d’entre eux sont définis par des conventions ouvertes et accessibles (et donc vérifiables par les personnes qui le souhaitent), certaines applications utilisent des protocoles propriétaires pas ou peu documentés. Il est alors difficile d’analyser les éventuelles informations sensibles que contiendraient les données échangées. Par exemple, Skype fonctionne comme une véritable boîte noire, qui fait ce qu’on veut (communiquer), mais possiblement beaucoup d’autres choses : il a été notamment découvert que le contenu des messages est analysé et éventuellement censuré214 et que toutes les adresses web qui sont envoyées via la messagerie sont transmises à Microsoft215.
26.2.4 Encapsulation
En réalité, différents protocoles sont employés simultanément lors d’une communication, chacun d’entre eux ayant un rôle dans l’acheminement des informations.
Il est courant de représenter ces différents protocoles en couches qui se superposent.
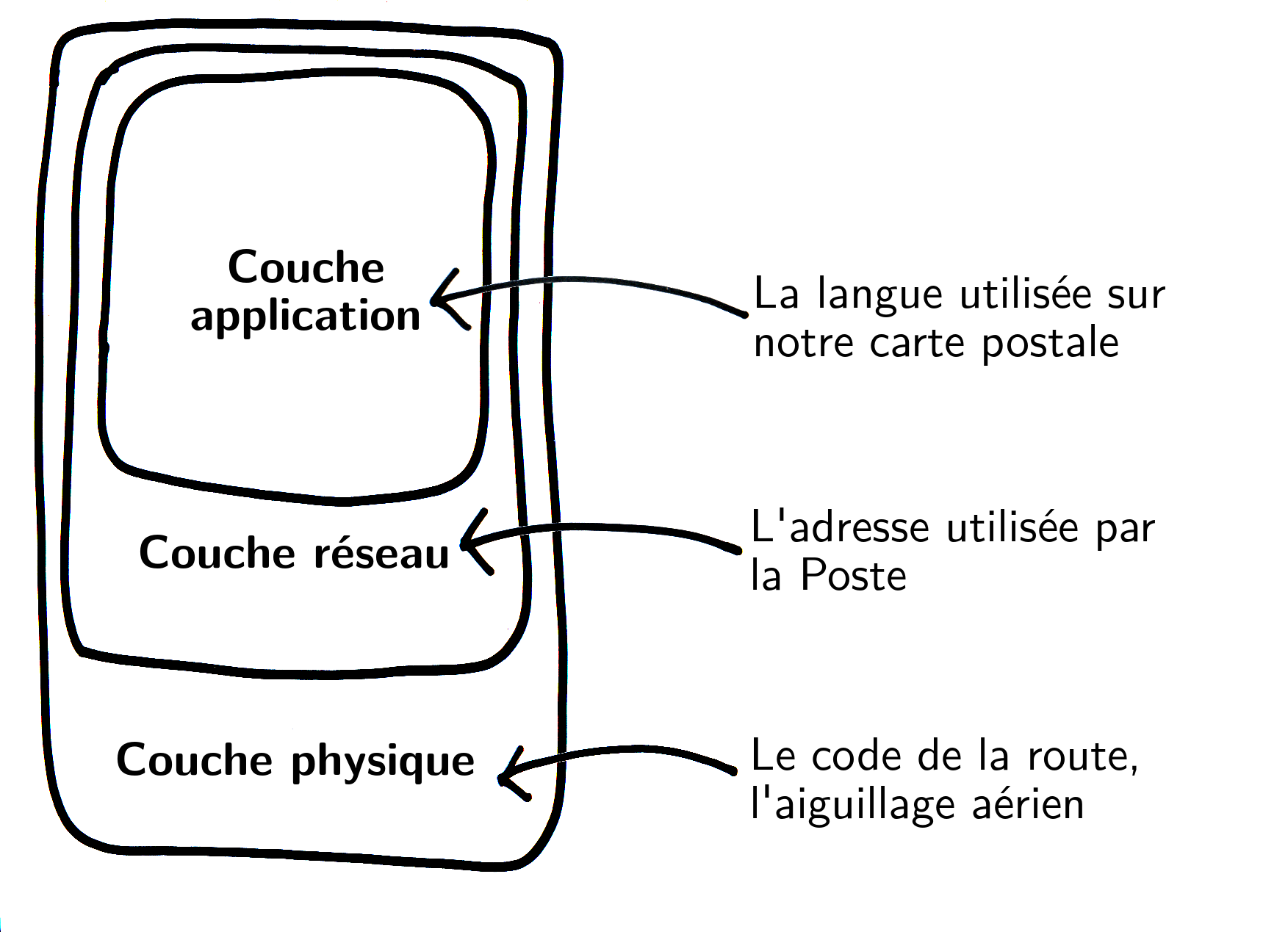
Des protocoles encapsulés
De fait, lorsqu’on communique par courrier, notre communication se base sur l’écriture (dans une certaine langue), puis sur l’acheminement par la Poste, qui s’appuie elle-même sur différents moyens de transport.
De manière similaire, une application d’Internet utilisera un protocole applicatif précis, sera aiguillée grâce à l’usage de protocoles réseau, et parcourra les différentes infrastructures en respectant les protocoles physiques en vigueur.
On parle d’encapsulation (l’action de « mettre dans une capsule ») : les protocoles applicatifs sont encapsulés dans les protocoles réseau, qui sont à leur tour encapsulés dans les protocoles physiques.
26.2.5 Plus de détails sur le protocole IP
Il est intéressant de remarquer que, contrairement aux protocoles physiques et applicatifs, les protocoles réseau sont relativement universels. Les protocoles physiques évoluent au gré des avancées technologiques, filaires ou sans-fil. Les protocoles applicatifs évoluent avec le développement de nouvelles applications : web, email, chat, etc. Entre ces deux niveaux, pour savoir par où passer et comment acheminer nos paquets à travers les millions de réseaux d’Internet, tout passe depuis les années 1980 par le protocole IP : Internet Protocol.
26.2.5.1 Paquets
Dans le protocole IP, les informations à transmettre sont découpées et emballées dans des paquets, sur lesquels sont écrites notamment l’adresse d’expédition et celle de destination. Cette « étiquette » sur laquelle sont écrites les informations utiles à l’acheminement des paquets, à l’aller comme au retour, est appelée l’en-tête du paquet. Les paquets d’informations sont ensuite transmis indépendamment les uns des autres, parfois en utilisant différents chemins, puis réassemblés une fois arrivés à destination.
En complément du protocole IP, il existe deux protocoles : TCP (Transmission Control Protocol) et UDP (User Datagram Protocol). TCP a été conçu pour transmettre des paquets sans perdre de données, en prenant le temps de tout vérifier. UDP assure la vitesse des échanges sans vérifier que les paquets arrivent à destination ; il est en particulier utilisé pour la vidéo- ou l’audio-conférence.
26.2.5.2 Adresse IP
Pour que cela fonctionne, tout ordinateur connecté au réseau doit avoir une adresse, qui est utilisée pour lui envoyer des paquets : l’adresse IP. Cette adresse doit être unique au sein d’un réseau. En effet, si plusieurs ordinateurs du réseau avaient la même adresse, le réseau ne pourrait pas savoir à quel ordinateur envoyer les paquets.
On peut comparer l’adresse IP à un numéro de téléphone : chaque poste téléphonique doit avoir un numéro de téléphone pour qu’on puisse l’appeler. Si plusieurs postes téléphoniques avaient le même numéro de téléphone, il y aurait un problème.
Les adresses utilisées depuis les débuts d’Internet se présentent sous la forme
de quatre nombres de 0 à 255, séparés par un point : on parle d’adresses IPv4 (Internet
Protocol version 4). Une adresse IPv4 ressemble à : 203.0.113.12.
Le protocole IPv4 a été défini au début des années 1980 et il permet d’attribuer au maximum 4 milliards d’adresses. À cette époque, on n’imaginait pas qu’Internet serait un jour accessible au grand public, et on pensait que 4 milliards, ce serait suffisant.
Dans les années 1990, pour faire face à la pénurie d’adresses qui s’annonçait,
l’IETF216 a commencé à travailler sur IPv6 (Internet Protocol version 6).
Depuis 2011 la pénurie est une réalité et il est difficile pour de nouveaux
opérateurs d’obtenir des adresses IPv4. Le protocole IPv6 est donc progressivement déployé
chez les opérateurs (même s’il y a des récalcitrants). La mise en place d’IPv6
implique des enjeux politiques considérables217, mais aussi de
nouvelles problématiques de sécurité218.
En 2022, les deux protocoles (v4 et v6) fonctionnent en parallèle.
Une adresse IPv6 ressemble à : 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
L’adresse IP est une information extrêmement utile pour quiconque cherche à surveiller ce qui se passe sur un réseau, car elle identifie un ordinateur du réseau de façon unique à un instant donné, sans pour autant être une preuve réelle219 contre une personne (car un ordinateur peut être utilisé par plusieurs personnes). Elle peut néanmoins indiquer l’origine géographique d’une connexion, donner des indices, amorcer ou confirmer des suspicions.
26.2.6 Port
On peut utiliser de nombreuses applications simultanément à partir d’un même ordinateur : lire ses emails dans le gestionnaire d’emails Thunderbird, regarder le site web de la SNCF, tout en tchattant avec ses potes par messagerie instantanée en écoutant de la musique en ligne. Chaque application doit recevoir seulement les paquets qui lui sont destinés et qui contiennent des messages dans une langue qu’elle comprend. Or, il arrive qu’un ordinateur connecté au réseau n’ait qu’une seule adresse IP. On ajoute donc à cette adresse un numéro qui permet à l’ordinateur de faire parvenir le paquet à la bonne application. On écrit ce numéro sur le paquet, en plus de l’adresse : c’est le numéro de port.
Pour comprendre, comparons notre ordinateur à un immeuble : l’immeuble n’a qu’une seule adresse, mais abrite de nombreux appartements, et différentes personnes. Le numéro d’appartement inscrit sur une enveloppe permet de faire parvenir le courrier à la bonne destinataire. Il en est de même pour les numéros de port : ils permettent de faire parvenir les données à la bonne application.
Certains numéros de port sont assignés, par convention, à des applications particulières. Ainsi, quand notre navigateur web veut se connecter à un serveur web, il sait qu’il doit toquer au port 80 (ou 443 dans le cas d’une connexion chiffrée). De la même façon, pour livrer un email, notre ordinateur se connectera en général au port 25 du serveur (ou 465 s’il s’agit d’une connexion chiffrée).
Sur l’ordinateur qu’on utilise, chaque application connectée à Internet ouvre au moins un port, que ce soit un navigateur web, un logiciel de messagerie instantanée, un lecteur de musique, etc. Ainsi, le nombre de ports ouverts dans le cadre d’une connexion à Internet peut être très élevé, et fermer son navigateur web est souvent loin d’être suffisant pour couper toute connexion au réseau…
Plus il y a de ports ouverts, plus il y a de points par lesquels des personnes malintentionnées ou des virus peuvent tenter de s’infiltrer dans un ordinateur connecté au réseau. C’est le rôle habituellement dévolu aux pare-feux (firewalls en anglais) que de ne laisser ouverts que certains ports définis dans leur configuration et de rejeter les requêtes allant vers les autres.
26.3 Les réseaux locaux
On peut faire des réseaux sans Internet. D’ailleurs, les réseaux informatiques sont apparus bien avant Internet. Dans les années 1960, des protocoles réseau comme HP-IB220, ne permettant de connecter qu’un nombre restreint d’ordinateurs, faisaient déjà fonctionner des réseaux locaux.
26.3.1 Le réseau local, structure de base de l’Internet
Quand on branche plusieurs ordinateurs entre eux dans une même maison, école, université, bureau, bâtiment, etc., on parle de réseau local (ou LAN, pour Local Area Network). Les ordinateurs peuvent alors communiquer entre eux, par exemple pour échanger des fichiers, partager une imprimante ou jouer en réseau.
On peut comparer les réseaux locaux aux réseaux téléphoniques internes de certaines organisations (entreprises, universités, etc.).
Ces réseaux locaux sont souvent composés de différents appareils qui communiquent entre eux :

Schéma d’un réseau local
26.3.2 Switch et point d’accès Wi-Fi
Pour relier les machines constituant un réseau local, on les connecte en général chacune à une « multiprise » réseau, que ce soit avec un câble ou par des ondes Wi-Fi. On utilise souvent un « switch », que l’on peut effectivement comparer à une multiprise. Cependant, au lieu de transmettre chaque paquet qui lui arrive à tous les ordinateurs branchés, un switch lit l’adresse indiquée sur le paquet pour ne l’envoyer qu’à la bonne prise de destination.
L’équivalent du switch des réseaux filaires s’appelle un « point d’accès » dans le monde sans-fil. Chaque point d’accès possède un nom, qui est diffusé aux environs (c’est la liste des réseaux Wi-Fi qu’affiche notre logiciel réseau).
Pour reprendre notre comparaison, le switch est un peu comme la factrice de quartier, qui va dispatcher le courrier, dans tout le quartier, à chaque destinataire. Pour cela, le switch traite les informations des cartes réseau, identifiées par leur adresse matérielle, branchées sur chacune de ses prises.
Tout comme l’accès physique à une machine donne beaucoup de possibilités pour récupérer les informations qui s’y trouvent, avoir accès physiquement à un réseau permet, sauf défenses particulières, de se faire passer pour l’une des autres machines de ce réseau. Cela rend possible de collecter beaucoup d’informations sur les communications qui y circulent, en mettant en place une attaque de type monstre du milieu. L’accès physique au réseau peut se faire en branchant un câble à un switch, mais aussi via un point d’accès Wi-Fi.
26.3.3 Adressage
Pour que les machines qu’on connecte au réseau puissent communiquer avec le protocole IP, elles doivent avoir chacune une adresse IP. Des logiciels et protocoles ont été développés pour automatiser l’attribution d’adresses IP aux ordinateurs lors du branchement à un réseau, comme par exemple les protocoles DHCP221 en IPv4 ou NDP222 et SLAAC en IPv6223.
Pour fonctionner, le système doit garder en mémoire l’association de telle carte réseau, identifiée par son adresse matérielle, à telle adresse IP. La correspondance entre l’adresse IP et l’adresse matérielle n’est utile que dans ce réseau local. Les adresses matérielles n’ont donc aucune raison technique de circuler sur Internet, mais cela arrive tout de même parfois224.
26.3.4 NAT et adresses réservées pour les réseaux locaux
Les organismes de standardisation d’Internet se sont rendu compte dans les années 1990 que le nombre d’adresses IPv4 disponibles n’allait pas être suffisant pour faire face à la croissance rapide du réseau. Pour répondre à ce problème, certaines plages d’adresses ont été réservées pour les réseaux privés et ne sont pas utilisées sur Internet : ce sont les adresses privées225.
Ainsi, la plupart des « box » Internet assignent
aux ordinateurs qui s’y connectent des adresses commençant par
192.168226 en IPv4 et par fe80: en IPv6. Plusieurs réseaux locaux peuvent utiliser les mêmes
adresses IP privées, au contraire des adresses IP sur Internet, qui doivent être
uniques au niveau mondial.
Les paquets portant ces adresses ne peuvent pas sortir du réseau privé
tels quels. Ces adresses privées ne sont donc utilisées que sur le
réseau local. Ainsi, par exemple, une machine peut avoir l’adresse IPv4
192.168.0.12 sur le réseau local mais, du point de vue des autres machines
avec qui elle communiquera par Internet, elle semblera utiliser l’adresse IPv4
de la « box » (par exemple,
203.0.113.48) : ce sera son adresse publique. C’est la « box » qui se charge
de modifier les paquets en conséquence, grâce à la traduction d’adresse
réseau (ou NAT, pour Network Address Translation).
26.4 Internet : des réseaux interconnectés
Internet signifie INTERconnected NETworks, c’est-à-dire « réseaux interconnectés ».
Chacun de ces réseaux est appelé système autonome (Autonomous System ou AS en anglais).
26.4.1 Fournisseurs d’accès à Internet
Le fournisseur d’accès à Internet (ou FAI) est une organisation offrant une connexion à Internet, que ce soit via une fibre optique, des ondes électromagnétiques227, une ligne téléphonique ou un câble coaxial. En France, les principaux fournisseurs d’accès à Internet commerciaux sont, pour un usage domestique, Bouygues, Orange, Free et SFR. Il existe aussi des FAI associatifs, tels que les membres de la Fédération FDN228.
Souvent, un FAI opère son propre réseau, auquel sont connectées les « box » des abonnées.
Pour connecter un réseau local à d’autres réseaux, il faut un routeur. C’est un ordinateur dont le rôle est de faire transiter des paquets entre deux réseaux ou plus.
Une « box » que l’on utilise pour raccorder une maison à Internet joue ce rôle de routeur. Elle dispose d’une carte réseau connectée au réseau local, mais aussi d’un modem ADSL ou d’un port fibre connecté au réseau du fournisseur d’accès à Internet : on parle de modem-routeur. Elle fait partie non seulement du réseau local, mais aussi d’Internet : en IPv4, c’est l’adresse IP de la « box » qui est visible depuis Internet sur tous les paquets qu’elle achemine pour les ordinateurs du réseau local. Inversement, en IPv6, toutes les machines connectées au réseau ont des adresses publiques routées et donc font partie d’Internet.
La « box » est un petit ordinateur qui intègre, dans le même boîtier que le modem-routeur, les logiciels permettant la gestion du réseau local (comme le logiciel de DHCP), ainsi qu’un switch Ethernet et/ou Wi-Fi pour brancher plusieurs ordinateurs mais aussi parfois un décodeur de télévision, un disque dur, etc.
26.4.2 Des systèmes autonomes
Un système autonome est un réseau cohérent — généralement sous le contrôle d’une entité ou organisation unique — capable de fonctionner indépendamment des autres réseaux.
En 2022, c’est l’interconnexion de plus de 72 000 AS dans le monde229 qui forme Internet.
Un système autonome peut typiquement être le réseau d’un fournisseur d’accès à Internet (par exemple Free, SFR ou tetaneutral.net). Dans ce cas, chaque « box » qui sert à connecter un réseau local domestique à Internet fait ainsi partie du réseau du fournisseur d’accès, qui est lui-même interconnecté à d’autres systèmes autonomes pour former Internet. Les organisations qui hébergent des services Internet (par exemple Gitoyen230, Google ou Riseup) et celles qui gèrent les « gros tuyaux » — comme les câbles transatlantiques par lesquels passe une grande partie des flux de données de l’Internet — possèdent aussi leurs propres systèmes autonomes.

Internet est une interconnexion de réseaux autonomes
Ainsi, Internet n’est pas un grand réseau homogène qui serait géré de façon centrale. Il est plutôt constitué d’une multitude de réseaux interconnectés gérés par des organisations et entreprises diverses et variées, chacune ayant son fonctionnement propre.
Tous ces réseaux, infrastructures et ordinateurs ne marchent pas tout seuls : ils sont gérés au quotidien par des personnes, appelées adminstratrices systèmes et réseaux, « admins » ou « adminsys »231. Les admins s’occupent d’installer, d’entretenir et de mettre à jour ces machines, donc elles ont nécessairement accès à beaucoup d’informations.
En termes de surveillance, les intérêts commerciaux et les obligations légales des systèmes autonomes sont très variées en fonction des États et des types d’organisation en jeu (institutions, entreprises, associations, etc.). Personne ne contrôle entièrement Internet, et son caractère mondial rend compliquée toute tentative de législation unifiée. Il n’y a donc pas d’homogénéité des pratiques.
26.4.2.1 Interconnexion de réseaux
De la même façon que l’on a branché notre réseau local au système autonome de notre FAI, celui-ci établit des connexions à d’autres réseaux. Il est alors possible de faire passer des informations d’un système autonome à un autre. C’est grâce à ces interconnexions que nous pouvons communiquer avec les différents ordinateurs formant Internet, indépendamment de l’AS auquel ils appartiennent.
)")
Un routeur
Un routeur est un ordinateur qui relie et fait communiquer plusieurs réseaux. Chez les opérateurs, les routeurs sont allumés en permanence et ils ressemblent davantage à de grosses boîtes de pizza qu’à des ordinateurs personnels ; leur principe de fonctionnement reste cependant similaire à celui des autres ordinateurs, et on leur adjoint quelques circuits spécialisés pour basculer très vite les paquets d’un réseau à un autre.
Les systèmes autonomes se mettent d’accord entre eux pour échanger du trafic ; on parle aussi d’accords de peering. Le plus souvent, le peering est gratuit, et l’échange est équilibré. Pour joindre les systèmes autonomes avec lesquels il n’a pas d’accord de peering, un opérateur peut avoir recours à un fournisseur de transit. Un fournisseur de transit est un opérateur qui sait joindre tout l’Internet et vend de la connectivité aux autres opérateurs232.
Il existe un principe qui interdit toute discrimination de trafic ; que ce soit à l’égard de la source, de la destination ou du contenu de l’information transmise sur le réseau. Il s’agit de la neutralité du Net. Ainsi, ce principe garantit aux internautes de ne faire face à aucune gestion du trafic Internet qui aurait pour effet de limiter leur accès aux applications et services distribués sur le réseau. Par exemple, limiter la consultation de vidéos en ligne ou le téléchargement. La neutralité du Net assure que les flux d’informations ne sont ni bloqués, ni dégradés, ni favorisés par les opérateurs de télécommunications, permettant ainsi d’utiliser librement le réseau233. En France, la Quadrature du Net234 et la Fédération FDN235 défendent et promeuvent la neutralité du Net236.
26.4.2.2 Des points d’interconnexion…
Avant, les opérateurs réseau tiraient des câbles directement entre leurs routeurs, ce qui faisait beaucoup de câbles, et beaucoup de frais. Ils utilsent désormais des points d’interconnexion (IX ou IXP, pour Internet eXchange Points), qui sont des endroits où de nombreux systèmes autonomes sont reliés entre eux. Les opérateurs qui veulent s’y connecter y amènent chacun une fibre et y installent des routeurs. Du fait de la quantité importante de trafic qui passe par ces lieux, ceux-ci sont d’une grande importance stratégique pour les États et autres organisations qui voudraient surveiller ce qui transite par le réseau.237
26.4.2.3 … reliés entre eux
Les grands centres d’interconnexion sont reliés par de gros faisceaux de fibres optiques. L’ensemble de ces liaisons forment les épines dorsales (backbones en anglais) d’Internet238.
Ainsi, pour relier l’Europe à l’Amérique, plusieurs faisceaux de fibres optiques courent au fond de l’océan Atlantique. Ces faisceaux de fibres sont autant de points de faiblesse, et il arrive de temps en temps qu’un accident, par exemple une ancre de bateau qui coupe un câble, ralentisse fortement Internet à l’échelle d’un continent239. Ça peut paraître étrange, vu qu’historiquement, l’idée d’Internet était d’inspiration militaire : un réseau décentralisé, qui multiplie les liens pour être résistant à la coupure de l’un d’eux.
26.4.3 Routage
Nous avons vu que les ordinateurs s’échangeaient des informations en les mettant dans des paquets.
Imaginons deux ordinateurs connectés à Internet sur des réseaux différents et qui veulent communiquer. Par exemple, l’ordinateur d’Ana, situé en France, se connecte à celui de Bea, situé au Venezuela.

Routage
L’ordinateur d’Ana accède à Internet par sa « box », qui se trouve sur le réseau de son fournisseur d’accès à Internet (ou FAI). L’ordinateur de Bea, lui, fait partie du réseau de son université.
Le paquet destiné à l’ordinateur de Bea arrivera tout d’abord sur le réseau du FAI d’Ana. Il sera transmis au routeur C de son FAI, qui joue le rôle de centre de tri. Le routeur lit l’adresse de l’ordinateur de Bea sur le paquet, et doit décider à qui faire passer le paquet pour qu’il se rapproche de sa destination. Comment s’effectue ce choix ?
Chaque routeur maintient une liste des réseaux auxquels il est connecté. Il envoie régulièrement les mises à jour de cette liste aux autres routeurs auxquels il est branché, ses voisins, qui font de même. C’est grâce à ces listes qu’il peut aiguiller les paquets reçus et les transmettre vers leur destination.
Ainsi, le routeur du FAI d’Ana sait qu’il peut joindre le réseau de l’université de Bea par quatre intermédiaires en envoyant le paquet au routeur D. Mais il peut aussi l’envoyer par deux intermédiaires, en le passant au routeur E. Il va choisir d’envoyer le paquet à E, qui a un chemin plus direct.
Le paquet arrive ainsi à E, le routeur d’un opérateur de transit, une organisation payée par le FAI d’Ana pour acheminer des paquets. E va faire le même genre de calcul, et envoyer le paquet à F. Le réseau de F comprend des ordinateurs non seulement en Europe, mais aussi en Amérique, reliés par un câble transatlantique. F appartient à une entreprise, similaire à celle qui gère E, qui est payée par l’université de Bea. F envoie finalement le paquet au routeur de l’université, qui l’envoie à l’ordinateur de Bea. Ouf, voilà notre paquet arrivé à destination.
Ainsi, chaque paquet d’information qui traverse Internet passe par plusieurs réseaux. À chaque fois, un routeur joue le rôle de centre de tri, et l’envoie à un routeur voisin. Au final, chaque paquet passe par beaucoup d’ordinateurs différents, qui appartiennent à des organisations nombreuses et variées.
De plus, la topologie du réseau, à savoir son architecture, la disposition des différents postes informatiques ainsi que leur hiérarchie changent au fil du temps.
Lorsque, le lendemain, Ana se connecte de nouveau à l’ordinateur de Bea, les paquets que son ordinateur envoie ne prendront pas nécessairement le même chemin que la veille. Par exemple, si le routeur E est éteint à la suite d’une coupure de courant, le routeur du FAI d’Ana fera passer les paquets par D, qui avait auparavant une route plus longue.
C’est en agissant au niveau du routage que le gouvernement égyptien a fait couper Internet lors de la révolution de 2011. Les routeurs des principaux fournisseurs d’accès à Internet du pays ont cessé de dire aux autres routeurs que c’est à eux qu’il fallait s’adresser pour acheminer les paquets vers les ordinateurs égyptiens240. Ainsi, les paquets destinés à l’Égypte ne pouvaient plus trouver de chemin, interrompant de fait l’accès au réseau, le tout sans avoir coupé le moindre câble.
26.5 Des clients, des serveurs
Historiquement, dans les années 1980, chaque ordinateur connecté à Internet fournissait une partie d’Internet. Non seulement il servait à « aller voir des choses sur Internet », mais il proposait également des informations, des données et des services aux autres utilisatrices connectées à Internet : il faisait Internet autant qu’il y accédait.
Le tableau général est très différent de nos jours. On a vu qu’il existe des ordinateurs allumés en permanence qui se chargent de relier des bouts d’Internet entre eux : les routeurs. De même, il y a une autre catégorie d’ordinateurs allumés en permanence qui, eux, contiennent presque toutes les données et services disponibles sur Internet. On appelle ces ordinateurs des serveurs, car ils servent des informations et des services. Ils centralisent la plupart des contenus, que ce soient des sites web, de la musique, des emails, etc. Cela induit de la verticalité dans la hiérarchie du réseau. En effet, plus on dispose d’information, au sens large, plus on a potentiellement de pouvoir.
Les serveurs fournissent, contrairement aux clients qui ne font qu’accéder aux informations. Cette situation correspond à un Internet où nos machines ont principalement un rôle de clients, centralisant Internet autour des fournisseurs de contenus241.
Prenons l’exemple d’un des services disponibles sur Internet, le site web du Guide d’autodéfense numérique : lorsqu’Ana consulte une page de ce site web, son ordinateur joue le rôle de client, qui se connecte au serveur qui héberge le Guide d’autodéfense numérique.
Cela dit, n’importe quel ordinateur peut être à la fois client et serveur, que ce soit dans un même temps ou successivement. C’est notamment le cas du modèle pair à pair, ou P2P, très utilisé pour le partage de fichiers. Dans cette situation, chaque ordinateur, autrement appelé nœud, est connecté au réseau et communique en jouant à la fois le rôle de client et celui de serveur. Ces deux usages ne sont pas déterminés par le type de machine.
26.5.1 Les serveurs de noms
Lorsqu’Ana demande à son navigateur web d’aller sur le site du Guide d’autodéfense numérique, son ordinateur doit se connecter au serveur qui héberge ce site.
Pour cela, il est nécessaire de connaître l’adresse
IP
du serveur. Or une adresse IP est une suite de nombres assez pénible à
mémoriser, à taper ou à transmettre, comme par exemple 88.99.208.38 (pour une
adresse IPv4). Pour
résoudre ce problème, il existe des serveurs à qui on peut poser des questions
telles que : « Quelle est l’adresse IP de guide.boum.org ? », comme on chercherait
dans l’annuaire téléphonique quel est le numéro d’une correspondante. Ce système
s’appelle le DNS (Domain Name System, ce qui donne « système de noms de
domaine » en français). L’ordinateur d’Ana commence donc, via sa « box », par
interroger le serveur DNS de son fournisseur d’accès à Internet pour obtenir
l’adresse IP du serveur qui héberge le nom de domaine guide.boum.org.
L’ordinateur d’Ana reçoit en retour l’adresse IP du serveur et peut donc communiquer avec celui-ci.
26.5.2 Chemin d’une requête web
L’ordinateur d’Ana se connecte alors au serveur du guide (88.99.208.38), et lui
envoie une requête qui signifie : « Envoie-moi la page d’accueil du site web
guide.boum.org. » Les paquets qui véhiculent la demande partent de son
ordinateur et passent alors par sa « box » pour arriver au routeur de son
fournisseur d’accès. Ils traversent ensuite plusieurs
réseaux et
routeurs (non représentés sur
le schéma), pour atteindre enfin le serveur de destination.
")
Schéma d’une requête web
26.5.3 Le logiciel serveur
Afin d’envoyer à Ana la page web demandée, le serveur recherche alors celle-ci dans sa mémoire, sur son disque dur, ou bien il la fabrique.
En effet, les pages consultables sur le web n’existent pas forcément sous une forme telle qu’on peut la voir sur notre ordinateur avant qu’on ait demandé à y accéder. Elle sont souvent générées automatiquement, à la demande. On parle alors de sites web dynamiques, par opposition aux sites web statiques, dont les pages sont écrites par avance.
Par exemple, si l’on cherche « ouistiti moteur virtuose » dans un moteur de recherche, celui-ci n’a pas encore la réponse en réserve. Le serveur exécute alors le code source du site pour calculer la page contenant la réponse avant de nous l’envoyer.
Sur le serveur, il y a donc un logiciel qui fonctionne, et qui répond lorsqu’on lui fait une requête. Ce logiciel serveur est spécifique à chaque application : c’est lui qui comprend le protocole applicatif. Dans le présent exemple, ce logiciel recherche et sert à l’ordinateur d’Ana la page web : on l’appelle donc un serveur web.
26.5.4 L’hébergement des serveurs
Les serveurs, ordinateurs sur lesquels fonctionnent les logiciels serveurs évoqués précédemment, sont en général regroupés dans des immeubles disposant d’une bonne connexion au réseau et d’une alimentation électrique très fiable : des centres de données (ou data centers en anglais).
)")
Une allée de serveurs dans un centre de données
De nos jours, la mode est de parler de cloud computing (ou « informatique en nuage » en français). Ce concept « marketing » ne remet pas en cause la séparation entre clients et serveurs, bien au contraire. Il signifie simplement que les données sont susceptibles d’être déplacées d’un serveur à un autre, pour des raisons légales, techniques ou économiques. Et cela sans que leurs propriétaires en soient nécessairement informées.

Il n’y a pas de cloud, seulement les ordinateurs d’autres personnes
La société Google possède par exemple au moins une vingtaine de data centers répartis sur trois continents242 afin d’assurer l’opérabilité de ses services 24 heures sur 24, 7 jours sur 7, même lorsque certains équipements sont indisponibles.
Les hébergeurs de ce type font tourner des centaines de machines physiques réparties dans plusieurs centres de données autour du monde et mettent en commun leur puissance de stockage et de calcul pour en faire une super-machine abstraite. Ensuite, ils vendent des « machines virtuelles », c’est-à-dire des parts de puissance de calcul et de stockage de cette super-machine. L’« Amazon Elastic Compute Cloud » (ou EC2) est l’un des services les plus connus dans ce domaine243.
Une machine virtuelle peut être déplacée automatiquement en fonction de l’utilisation des machines physiques, de la qualité de leur connexion au réseau, etc. Avec une telle infrastructure, il est impossible de savoir à l’avance sur quelle machine physique — et donc précisément à quel endroit — se trouve une machine virtuelle donnée.
Cela rend en pratique impossible d’avoir du contrôle sur nos données244. Seront-elles réellement effacées des machines physiques si on les « supprime » ? On a vu dans le premier tome qu’effacer des données sur un ordinateur était quelque chose de compliqué. Ce problème se corse encore plus si nous ne savons pas de quel ordinateur il s’agit. De plus, cela pose des problèmes juridiques : des données légales à un endroit peuvent se retrouver illégales parce que la machine qui les contient ou les sert sur Internet a changé de juridiction.
Il y a donc eu un glissement d’un Internet où tout le monde consultait et distribuait des données, vers un modèle où les données étaient centralisées sur des machines physiques appelées serveurs, puis aujourd’hui vers le cloud, où ces mêmes données peuvent être enregistrées, parfois éparpillées, sur des serveurs indéterminés. Il devient extrêmement compliqué de savoir au final où elles sont réellement stockées, et l’utilisatrice a encore moins de prise sur le devenir de ses données.
Pour une explication en cinq minutes : Rémi explique, 2015, Internet ! Comment ça marche ?. Pour une explication détaillée en quatre heures : Benjamin Bayart, 2012, Qu’est-ce qu’Internet ? – Cycle de conférences à Sciences Po.↩︎
Selon Benjamin Bayart, « on ne peut pas dissocier Internet et logiciel libre » car ils sont apparus aux mêmes dates, avaient les mêmes acteurs, une croissance et un fonctionnement similaires. Benjamin Bayart, 2007, Internet libre, ou Minitel 2.0 ?, conférence aux 8es rencontres mondiales du logiciel libre, Amiens.↩︎
Jérôme G., 2012, Caméras IP : faille du voyeur comblée, Génération-NT.↩︎
Korben, 2013, Les radars pédagogiques à la merci des pirates ?.↩︎
Ouest-France avec AFP, 2020, Paris. Il piratait les bornes de jeux de grattage du PMU et de la FDJ dans les bars.↩︎
Fabien Soyez, 2013,Vie privée : télé connectée, l’espion parfait, CNET France.↩︎
Camille Kaelblen, 2016, Votre frigo connecté est-il la porte d’entrée idéale pour les hackers ?, RTL.↩︎
Gilles Halais, 2012, Un hacker a trouvé comment pirater à distance les pacemakers, Franceinfo.↩︎
Sandrine Cassini, 2015, Les jouets VTech victimes d’un piratage, Le Monde.↩︎
Paul Ackermann, 2015, Une voiture piratée à distance par des hackers, HuffPost.↩︎
Guillaume Ledit, 2017, Sur Twitter, « Internet of Shit » ridiculise l’Internet des objets… merdiques, Usbek & Rica.↩︎
Une adresse MAC se présente sous la forme d’une suite de 12 chiffres hexadécimaux (de
0à9, puisapour 10,bpour 11, et ainsi de suite jusqu’àfpour 15) comme par exemple00:3a:1f:57:23:98.↩︎« Modem » est le mot condensé de modulateur-démodulateur : il permet de transmettre des données numériques sur un canal permettant de véhiculer du son, comme par exemple une ligne téléphonique.↩︎
Une fibre optique est un fil constitué d’un matériau transparent permettant de transmettre des données sous forme d’impulsions lumineuses. Cela permet la transmission d’importants volumes d’information, même sur de longues distances.↩︎
L’ADSL (pour Asymmetric Digital Subscriber Line) ou VDSL (pour Very-high-bit-rate Digital Subscriber Line) est une technologie permettant de transmettre des données numériques sur une ligne téléphonique de manière indépendante du service téléphonique.↩︎
Ces documents publics sont des Request For Comments. Le site Commentcamarche explique très bien le concept de RFC. Jean-François Pillou, 2011, Les RFC, CommentCaMarche.↩︎
En réalité c’est un peu plus compliqué. Pour plus de détails voir : Wikipédia, 2017, Suite des protocoles Internet.↩︎
Il existe une différence notable dans les protocoles employés, qui a des conséquences en termes de confidentialité et d’anonymat, selon qu’on utilise une boîte mail par le biais de son navigateur web (webmail) ou par le biais d’un client de messagerie. Tout cela sera développé plus loin.↩︎
Ryan Gallagher, traduit par Cécile Dehesdin, 2013, « Lance des œufs », « cinéma coquin »… La liste des mots surveillés par Skype en Chine, Slate.fr.↩︎
Jürgen Schmidt, 2013, Skype’s ominous link checking: Facts and speculation, The H (en anglais).↩︎
Dans cette conférence, LDN explique les enjeux du basculement vers IPv6.↩︎
Cette nouvelle norme pose de nouveaux problèmes vis-à-vis de notre anonymat en ligne. Florent Fourcot, 2011, IPv6 et conséquences sur l’anonymat, LinuxFr.org. À suivre, donc…↩︎
Legalis, 2013, L’adresse IP, preuve insuffisante de l’auteur d’une suppression de données sur Wikipedia.↩︎
Utilisé dans les réseaux IPv4, DHCP signifie « protocole de configuration dynamique d’hôte » (Dynamic Host Configuration Protocol en anglais).↩︎
Wikipédia, 2022, IPv6, section « Attribution des adresses IPv6 ».↩︎
L’un des cas où l’adresse matérielle circule sur Internet est l’utilisation de portails captifs, dont on parlera plus tard.↩︎
En même temps, l’IETF travaillait sur la version 6 du protocole IP qui résout le problème de pénurie.↩︎
Les plages d’adresses privées sont définies par convention dans un document appelé « RFC 1918 ». Elles incluent, en plus des adresses commençant par
192.168, celles qui commencent par10et de172.16à172.31.↩︎Wi-Fi, 4G ou autre…↩︎
On peut trouver de jolies statistiques sur l’évolution des AS sur le site du CIDR Report (en anglais).↩︎
Association qui fournit des services à Globenet, à plusieurs membres de la Fédération FDN, et à plusieurs Chatons. Plus d’informations sur son site.↩︎
On parlera plus loin d’« admins » pour désigner les administratrices systèmes et réseaux.↩︎
Loïc Komol, 2013, Le peering : petite cuisine entre géants du Net, Clubic.↩︎
#DataGueule a fait une vidéo qui explique clairement la neutralité du Net et les enjeux politiques associés.↩︎
La neutralité du net est définie en droit français dans l’article L33-1 du Code des postes et des communications électroniques.↩︎
Guillaume Champeau, 2013, Comment l’Allemagne aussi espionne nos communications, Numerama.↩︎
TeleGeography, 2017, Submarine Cable Map (en anglais).↩︎
Pierre Col, 2009, Internet, les ancres de bateaux et les séismes sous-marins, ZDNet, Cécile Dehesdin, 2013, Des coupures dans des câbles sous-marins ralentissent Internet dans plusieurs pays, Slate.fr.↩︎
Stéphane Bortzmeyer, 2011, Coupure de l’Internet en Égypte.↩︎
La conférence de Benjamin Bayart Internet libre, ou Minitel 2.0 ?, donnée aux 8es rencontres mondiales du logiciel libre à Amiens en 2007, explique très bien ce glissement et les enjeux qu’il recouvre.↩︎
Google, 2017, Data center locations (en anglais).↩︎
Jos Poortvliet, 2011, openSUSE and ownCloud (en anglais).↩︎